Building a Voice-Enabled Financial Chatbot with MCP and Vector Search on YugabyteDB
As financial services evolve, there’s increasing demand for intelligent, real-time, personalized customer interactions. This blog outlines how we built a voice-enabled financial chatbot using YugabyteDB with pgvector, OpenAI embeddings, and the Model Context Protocol (MCP).
It also highlights how semantic search, when paired with a structured conversational framework like MCP, enables highly relevant and user-specific AI interactions – all while operating over transactional OLTP data stored in YugabyteDB.
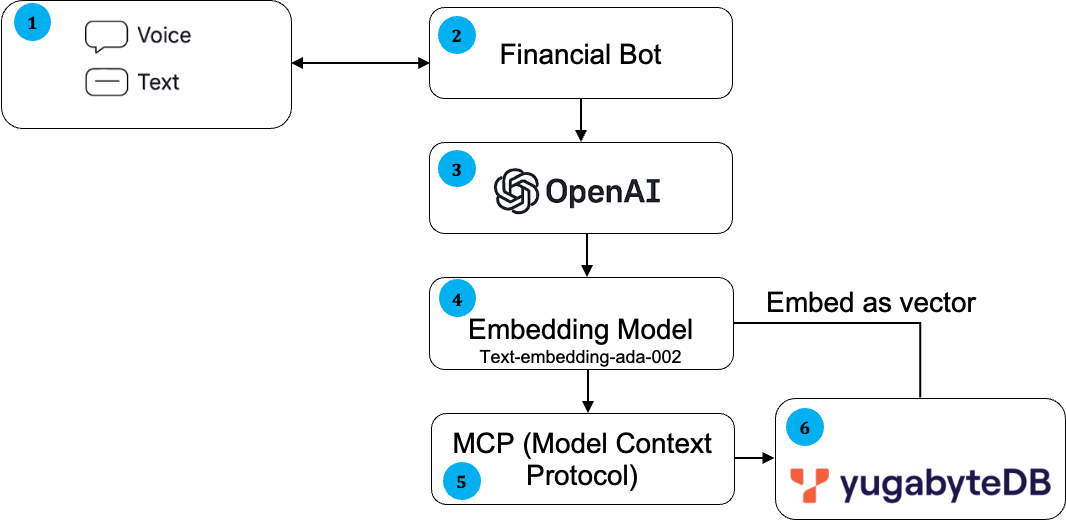
Our financial chatbot’s architecture combines voice AI components with a backend powered by LLMs and a YugabyteDB database. This high-level workflow involves several steps and components working together.
Figure 1 – Data Flow and Architecture
Data flow seq#
Operations/Tasks
Component Involved
1
Users interact via voice. Speech is converted to text using a speech-to-text engine.
After the AI generates a response, it’s vocalized through text-to-speech, enabling a smooth conversational experience.
HTML, Java Script
2, 3, 4, 5
A large language model (LLM) processes the user’s query, enhanced by Model Context Protocol (MCP) to perform structured tasks like database queries or calculations.
The MCP server acts as a bridge, exposing tools like GetLatestTransactions(userID) that the AI can invoke to retrieve relevant data from SQL or vector search in YugabyteDB.
The AI then uses this data to craft accurate responses, which are spoken back to the user.
Node JS, Open AI API
6
Structured and unstructured data are stored in YugabyteDB.
Text data embeddings are indexed using the pgvector extension to enable semantic search across FAQs, product info, and more.
MCP provides a structured way for client applications to interact with language models, reducing the need for custom integration logic like LangChain or LlamaIndex. Instead of writing ad hoc prompt chaining or context assembly code, developers can rely on MCP to define clean roles and prompt structures, while still using standard tools (like SQLAlchemy or pgvector) on the backend as needed.
In this case, OpenAI (GPT Model). The MCP server processes the structured prompt:
Understands the contextual blocks (e.g., system message, memory, user query)
Responds as a helpful, role-bound assistant based on the defined prompt and context
By splitting responsibilities cleanly between the MCP client and server, we achieve:
User specificity: Ensures every query is grounded in the right user’s data (e.g. user_id column in document table. For more information, refer to the YugabyteDB data model section below
Contextual grounding: Retrieves top-N transactions using vector similarity
Structured prompting: Promotes consistency and safety in responses
Explainable behavior: Each part of the response is traceable to specific prompt blocks
This pattern not only enables explainable AI, but also ensures reliability, personalization, and trust – proving the power of MCP in production-grade AI interfaces.
YugabyteDB’s PostgreSQL compatibility and native support for pgvector, allows embedding directly within a scalable, distributed database, the need for without additional vector engines.
The snippet below shows the data model of a chatbot that uses transactions and document tables.
[yugabyte@yb-dev-bseetharaman-dc-test-n1 ~]$ ./ysqlsh -h $(hostname -i)
ysqlsh (15.2-YB-2.25.1.0-b0)
Type "help" for help.
yugabyte=# \d
List of relations
Schema | Name | Type | Owner
--------+---------------------+----------+----------
public | documents | table | yugabyte
public | documents_id_seq | sequence | yugabyte
public | transactions | table | yugabyte
public | transactions_id_seq | sequence | yugabyte
public | users | table | yugabyte
public | users_id_seq | sequence | yugabyte
The transactions table stores the payment transactions of different customers (user_id) for different merchants.
yugabyte=# \d transactions
Table "public.transactions"
Column | Type | Collation | Nullable | Default
----------+---------+-----------+----------+------------------------------------------
id | integer | | not null | nextval('transactions_id_seq'::regclass)
user_id | integer | | |
amount | numeric | | |
merchant | text | | |
category | text | | |
txn_date | date | | |
Indexes:
"transactions_pkey" PRIMARY KEY, lsm (id ASC)
yugabyte=# select * from transactions limit 2;
id | user_id | amount | merchant | category | txn_date
----+---------+--------+----------+---------------+------------
1 | 44 | 399.98 | Apple | entertainment | 2024-01-22
2 | 35 | 176.85 | Netflix | electronics | 2024-02-01
(2 rows)
yugabyte=#
The documents table is used for storing vectorized summaries.
yugabyte=# \d documents
Table "public.documents"
Column | Type | Collation | Nullable | Default
-----------+--------------+-----------+----------+---------------------------------------
id | integer | | not null | nextval('documents_id_seq'::regclass)
content | text | | |
embedding | vector(1536) | | |
user_id | integer | | |
txn_date | date | | |
Indexes:
"documents_pkey" PRIMARY KEY, lsm (id ASC)
yugabyte=#
Load_transactions.py: Generates sample payment transactions and loads them into the transactions table of YugabyteDB.
seed-doc.js: Fetches transaction records, converts them to natural language, embeds them using OpenAI, and stores them in the documents table for vector search.
server.js: Acts as the MCP client – handles user queries, enriches them with context, retrieves relevant documents via pgvector from YugabyteDB, and queries OpenAI for responses.
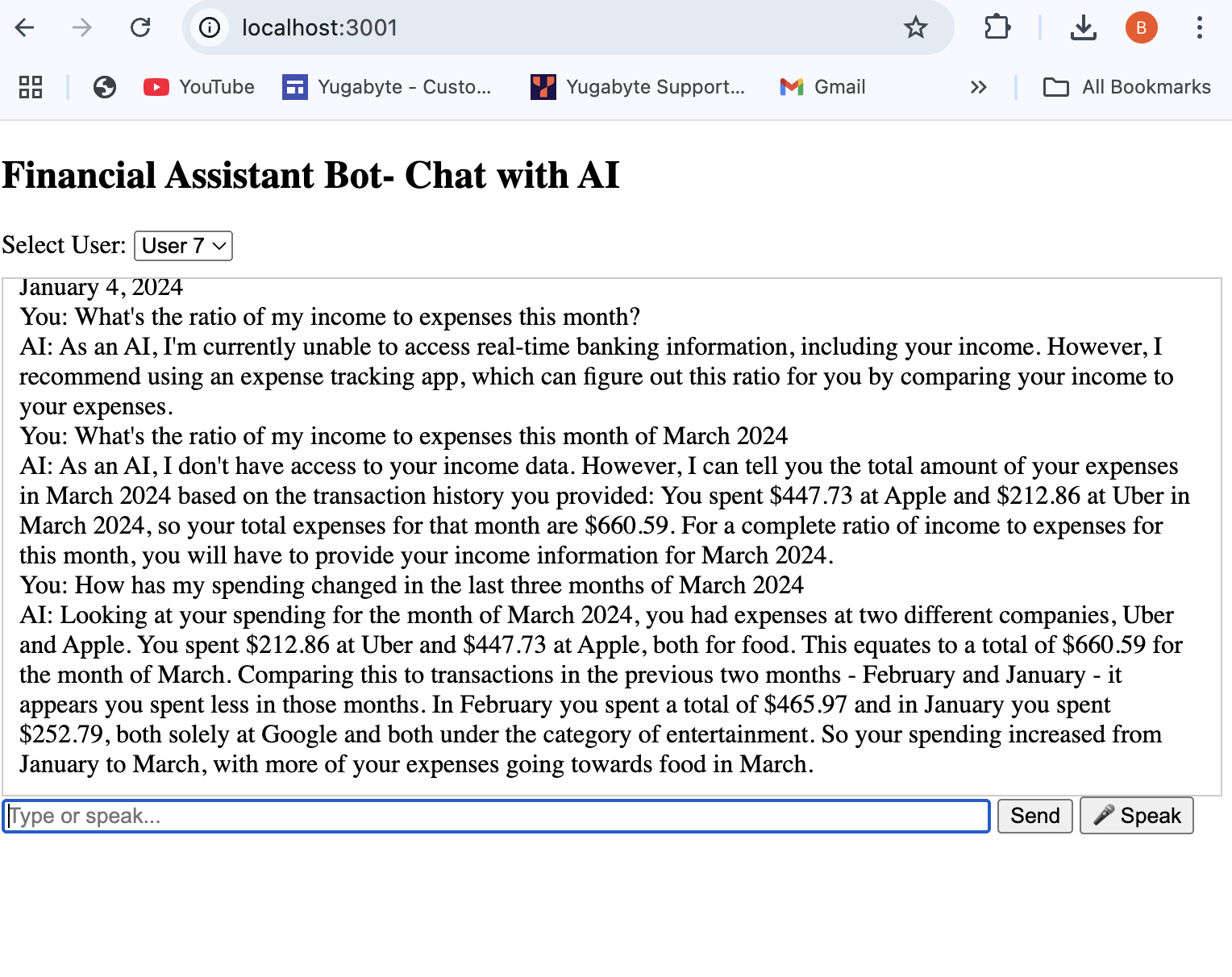
Output
The application screen below shows the financial assistant bot (voice/text enabled) deployed in Node JS.
This blog illustrates how YugabyteDB, OpenAI, and MCP can be used together to build a modern, scalable, and intelligent chatbot for financial insights. By combining transactional data, vector embeddings, and conversational AI, we have created a solution that is both technically elegant and user-centric.